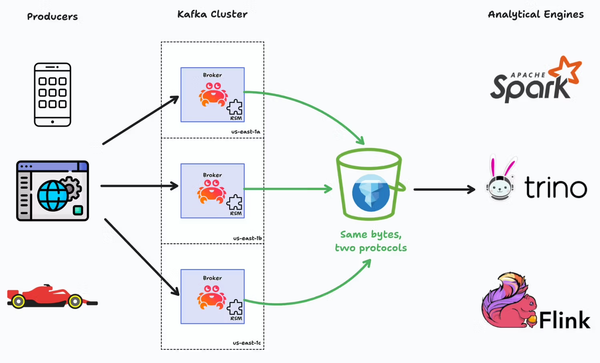
If you want to showcase real-time data architectures you need a data source that's live, high-volume, varied, and messy enough to showcase real-world challenges. This is an issue I've run into several times over the last year whilst giving talks about real-time analytics using Kafka, Druid,